AI-enabled agile delivery: twenty agents, ready to fork.
From the daily standup to the leadership table. The repo has every build spec. The hard half is the culture honest enough to use them.
TL;DR. I started writing a setup guide for four delivery agents and ended up with twenty, all buildable on the stack you already have. The hard half is the culture honest enough to use them.
Once, I spent time with a department where passion went to die and high-performing employees turned into 'mushrooms'. Role clarity changed shape every day. You had to become part of the tribe to stay. And transparency was transparent until it hit the middle managers.
If that is your team, I am sorry. No agent fixes a team like that, because the agents amplify what is already there. If you are not that team or you want to stop being one, earlier this month I wrote about the opposite kind of team. The dream is buildable today on a stack most delivery teams already have. After that piece I started a setup guide for the four agents named in it. By the time I sat down to write the second draft, I knew the four were not enough.
Twenty agents organised across three tiers: the team running Scrum, the Scrum of Scrums where two to seven teams align, and the LT cadence where the unit of work is the quarter. The catalogue is the shape, not a checklist, so pick the one that buys back the most time on your team first.
One precondition before you read further. The agents read what your team already records in your systems: tickets in Jira, retros in Confluence/Miro, OKR check-ins in a sheet/Confluence, customer feedback in a tagged channel/Confluence/Jira. If those things do not exist, or are not organised in your tools, no agent here will save you. The catalogue assumes the pre-setup is done.
The toolchain in one paragraph
The Model Context Protocol (MCP) did not exist a year ago, and it is now doing the heaviest lifting. It gives your runtime a standard way to read and write to Jira, Confluence, GitHub, Miro, Slack, Teams, your CI/CD pipeline, your metrics warehouse, the OKR sheet, the CRM, and your customer-feedback channels for the bigger agents, without you writing custom integration code for each one. The other two pieces of the stack you probably already have: a runtime (the AI assistant in your IDE or terminal) and the systems it reads from.
The first-party MCP servers from Jira, Confluence, GitHub, and Miro just work. Miro shipped theirs in late 2025 and connects cleanly to Claude Code, Cursor, Codex, and the rest of the modern AI-coding stack. Slack has community servers that work but need permission tuning and the bot-token scopes most enterprise IT will not grant first time. Microsoft Teams is the weakest leg as of mid-2026, with no general-purpose Teams MCP server that has parity to the Slack story, so you will probably need a thin custom adapter or a Power Automate or Graph feed until Microsoft ships proper support. You connect once and every agent inherits the connection. If you have not set up MCP yet, your runtime's docs will walk you through it.
I would not call any of this experimental any more. GitHub's Octoverse 2025 reports more than 1.1 million public repositories importing an LLM SDK, a 178% year-on-year increase. Half of open source projects have at least one maintainer using GitHub Copilot. Whatever you decide to build, you will be building it on a stack thousands of teams already use.
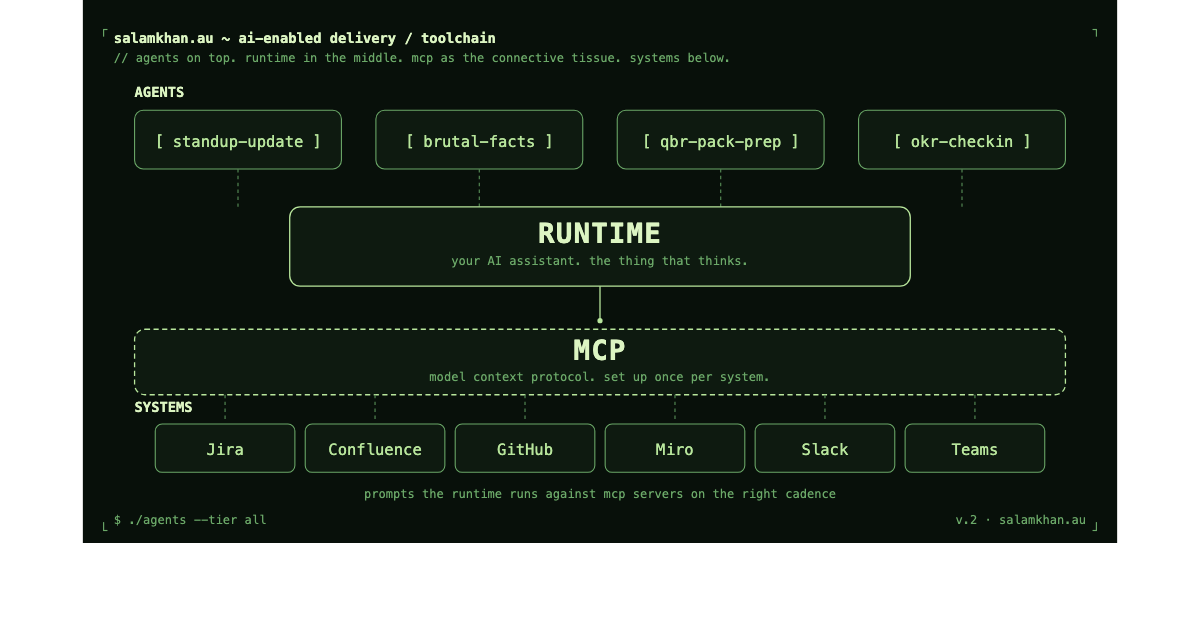
The toolchain in one picture. The four agents shown are illustrative. The full catalogue is below. Generated by Author using Claude.
That is the whole stack: the runtime in the middle, MCP servers around the edge. Agents are prompts the runtime runs against the right MCP servers on the right cadence. Every agent in this article is a variation on that one shape.
A scheduler
The runtime in your IDE only runs when you open the IDE. Any agent with a daily or weekly cadence needs something to fire it on time. I look at the choice as three paths depending on how far in I want to go.
Start manual if the agent is new. Open your IDE in the morning, run the prompt yourself, paste the output into the team channel. No scheduler, no server, no auth review. This is how you test whether a new agent is worth the trouble before you wire anything up. If it does not save you time when you press the button yourself, it will not save you time on a schedule either.
Use what your IDE gives you if you can. Claude Code, Cursor, and Codex all let you run a prompt as a slash command, a saved task, or a scheduled run. Check your IDE's docs. If it has a built-in scheduler, use it. Less to set up.
Schedule it from outside when you want it running while you sleep. Set up a cron job on a laptop, a Mac mini under your desk, or a cheap VPS. Have it call the CLI for your runtime (claude, codex, whichever you use) or the runtime's API. Workflow tools you already pay for (n8n, Make, Pipedream, GitHub Actions on a cron schedule) work too. This is where most teams end up once the first agent has proven itself.
On cost
The runtime tokens are a few cents per agent per run, which is real but small relative to the time the room saves. The MCP servers come free or self-hosted, on systems you already pay for.
I see the bigger cost as cultural, not financial. Companies still treat IT as an expense to control rather than an investment to compound. Watching that happen up close has been one of the more frustrating parts of the last decade for me. When I bring this up in conversation, some leaders push back. Not because the bill is large but because the line item is unfamiliar. The runtime is the cheap part. Persuading a leadership team this is worth funding is the part that takes the time. That is the missed opportunity I see most often in the orgs I have worked with and the one that costs the org more than the tokens ever will.
The 2024 DORA Accelerate State of DevOps Report put the trade-off directly. 75.9% of respondents reported productivity gains from AI. The same report measured a 1.5% drop in delivery throughput and a 7.2% drop in delivery stability when AI adoption rose without the surrounding discipline. The lift is real. The tax on stability is real too. The agents in this catalogue are designed for the discipline side: read-only first, draft-not-decide, shadow mode, scoreboard truth. Build them with the discipline and you keep the lift without the tax.
Three tiers
I grouped these into three tiers because twenty agents is too many to read in one sitting and they are not all running for the same person.
Tier 1: Team Scrum cadence. Single team, sprint-aligned. The audience is the dev team, the product owner, the scrum master, the engineering lead. The agents in this tier feed the Daily Scrum (the standup), fortnightly planning, ongoing refinement, review, retro, plus the Sprint Goal commitment. Most delivery teams I have worked with would start here.
Tier 2: Scrum of Scrums and multi-team coordination. Two to seven teams running on a shared cadence and needing to align. The audience is the program manager, the RTE if you are running SAFe, the group product manager, the principal engineer. The agents in this tier roll up the team-level signal and watch the seams between teams: dependencies, integrations, multi-team risk. If you are running plain multi-team Scrum rather than SAFe, read "program manager" wherever I say RTE. Pure Scrum has no RTE role.
Tier 3: the LT cadence. Anything where the unit of work is the quarter, not the sprint. The audience is the head of product, the GM, the COO, the steering committee, the board. The agents in this tier prepare the artefacts the leadership table wants: planning packs at the start of the quarter, review packs at the end, OKR check-ins each week, roadmap deltas each month, win/loss synthesis, portfolio readouts.
If you run one team, stop at Tier 1. A program needs Tier 1 plus Tier 2. A product or a function across teams needs all three. The agents are the same shape at every tier. Only the data they read and the people they write for change.
If your team is on Kanban rather than Scrum, the cadence labels change but the agent shapes do not. A Kanban team has a daily flow review instead of a Daily Scrum. Translate the cadence, keep the agents.
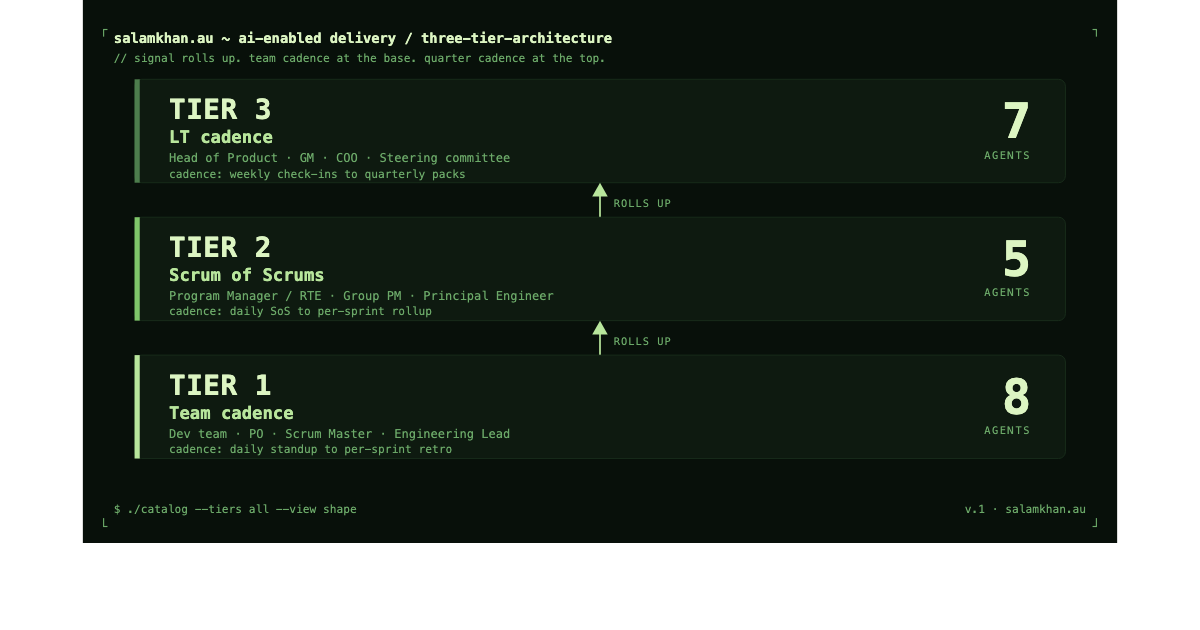
The catalogue in three tiers. Eight agents at the team cadence. Five at the Scrum of Scrums. Seven at the leadership cadence. Signal rolls up. Generated by Author using Claude.
A quick note on Scrum vocabulary
The catalogue uses a mix of Scrum Guide language and team conventions. I should name which is which before the agent rows start using both.
In the Scrum Guide. The Sprint Goal is the commitment of the Sprint Backlog. The Product Goal is the commitment of the Product Backlog. The Definition of Done is the commitment of the Increment. Three commitments, all canonical, all named in the Guide. The events are Sprint Planning, the Daily Scrum, the Sprint Review, and the Sprint Retrospective. Product Backlog Refinement is named in the Guide as an ongoing activity rather than a fixed event, though most teams schedule a recurring session.
Team conventions, used here, not canonical. The Definition of Ready is a team agreement. Velocity is a team convention. Scrum of Scrums is a coordination convention. SAFe layers more vocabulary on top (PI Planning, the System Demo, the ART Sync). I lean on whichever one the cadence event needs.
The agents in this catalogue enforce what your team has agreed on, not what the Scrum Guide prescribes. If your team disagrees on what Done or Ready means, that conversation comes before any agent that watches either one. The agent reads your conventions. It cannot invent them for you.
What changed since the dream-team piece
The original article named four primary agents and five future ones. Here are the verdicts.
standup-update-agent: take. Spine of the catalogue. Already has a deeper how-to in make your standup a planning event again. Tier 1.
project-or-product-updates-agent: split. At single-team scale this overlaps with the standup-update. At multi-team scale it becomes the multi-team-sprint-rollup. At leadership scale it becomes the QBR pack and the portfolio bets readout. The pattern survives, the agent name does not. Lifted into Tier 2 and Tier 3 in different forms.
pragmatic-brutal-facts-agent: take. Reads drift, not state. Posts before standup. Held up cleanly. Tier 1.
transparency-scoreboard: take, recast. Not an LLM, never was. A read-only dashboard with no admin override. The substrate every other agent points at, not an agent in its own right. Has its own short section below.
health-check-agent: deprecate. Surveillance risk on chat tone and 1-on-1 notes is severe. The signal is real, the engineering is hard, the failure mode is bad. I am not going to tell you to build this one. A section below explains why.
DORA-metrics-agent: take. Now team-dora-agent in Tier 1. Four numbers, one card, weekly. No reason to change.
team-performance-agent: park. Brutal-facts and team-dora cover enough of the same ground at single-team scale. Lifted to Tier 2 as chapter-throughput-agent, parked in the repo's agents/also-considered/ rather than the main article. It is buildable. It is just narrower than the rest of Tier 2 and needs more team-level data hygiene to be useful.
retrospective-synthesis-agent: take, plus a sibling. The longitudinal version is right. Added a per-sprint retro-prep-agent because per-sprint prep and quarterly synthesis are different jobs.
risk-radar-agent: lifted. A single-team risk-radar still does the job where there is no PM keeping a RAID register. Lifted here as program-risk-radar-agent because cross-team risk is where dependencies, integrations, and milestones compound.
Tier 1. Team Scrum cadence agents
Eight agents in this article for a single team running on a sprint cadence, plus one more in the repo. The agents feed the events Scrum names and the Sprint Goal commitment between them.
standup-update-agent
- The agent that writes the overnight one-pager so the team walks into standup already informed.
- Reads commits and PRs since the previous evening, Jira ticket transitions on the active sprint board, Slack or Teams team-channel messages, the active Sprint Goal.
- Produces a one-page markdown post in the team channel: shipped, stalled, sprint-goal trajectory, likely standup talking points. Every claim links back to a commit or a ticket.
- Cadence is daily, generated 6-8am team-time, posted before 9am.
- Audience is the whole dev team, product owner, scrum master, engineering lead.
- Pain it removes is the round-the-room status ritual.
- I went deeper on this one in make your standup a planning event again. The deep-dive carries the load.
- Verdict: take.
pragmatic-brutal-facts-agent
- The agent that reads drift, not state. The other Tier 1 agents tell you what is happening now. This one tells you what is moving wrong.
- Reads a rolling 60-90 day metric baseline computed from Jira (cycle time, lead time, sprint scope churn, commitment-vs-delivery delta, story carry-over), GitHub (PR review time, PR reopen, merge frequency), the bug tracker (reopen rate, defect age), and the customer escalation queue if you have one.
- Produces a short flag list, one sentence per flag, in the team channel. Names the trend and the magnitude. Cycle time has jumped from 3.2 to 5.8 days over the last seven sprints. Does not infer cause. Does not propose fix.
- Cadence is daily, posted 6:30-7am so it lands before the standup-update.
- Audience is the whole dev team, scrum master, engineering lead.
- Pain it removes is retro archaeology, the discovery weeks late that something started breaking five sprints ago.
- Verdict: take.
refinement-prep-agent
- Before refinement, this agent has already done the first-pass story drafting. The product owner walks into the morning with draft stories already in the backlog, shaped from the Epic and from the pattern of stories the team has Done before. The PO sharpens those drafts based on judgement and context the agent does not have. The team walks into the session and spends the hour on the real conversations: should this be one story or two, what does Done mean here, how does this story land for the customer. The PO stops typing acceptance criteria from scratch. The team stops watching the PO type. Highest-impact Tier 1 add.
- Reads the parent Epic (description, Epic-level acceptance criteria, linked design pages in Confluence, parent Initiative), previous stories Done under this Epic and under similar Epics (their titles, acceptance criteria, and story-point estimates, which form the pattern library the agent learns from), the current backlog under the Epic (what is already there, what is missing), the team's Definition of Ready as the bar to draft against, the component / ownership matrix in Confluence, and any technical spike outcomes or customer-feedback items linked to the Epic.
- Produces two outputs. First, draft new stories created in the Jira backlog under the Epic. Each one is labelled
agent-draftedand left in the default Backlog status, with a parent-epic link, a draft title, draft acceptance criteria in Given/When/Then form, a rough story-point estimate, a component inherited from the Epic, and a notes section explaining which prior stories the pattern came from. The sprint-planning view filters out theagent-draftedlabel via a JQL clause, so the story cannot be pulled into a sprint by accident until the PO accepts it and removes the label. Second, the existing refinement agenda in the team channel and pinned to the Confluence refinement page: ready-to-refine items (with what is missing per item), parking lot (these need a PO conversation first), already DoR-clean (skip in session). - Cadence runs when an Epic is signed off and again the morning of refinement.
- Audience is the product owner and product manager as primary reviewers, tech lead for technical sanity, dev team for the final pass in the session.
- Final call is always the PO's. The agent drafts. The PO accepts, edits, or rejects. The team refines whatever the PO promotes.
- Verdict: new. This is the agent that breaks the read-only-first principle by design (it has to write to Jira to create stories). Run the first version in shadow mode: it drafts in plain text and posts the drafts to a channel for the PO to create the Jira tickets manually. After a week of the PO trusting the output, enable Jira write access where the agent creates tickets in the Backlog tagged
agent-drafted. The label is the safety gate, filtered out of the sprint-planning view. Agent-drafted stories never enter a sprint until the PO accepts them and removes the label.
sprint-planning-prep-agent
- Before Sprint Planning, this agent has already done the goal drafting and the capacity maths. The product owner walks in with two or three draft Sprint Goal candidates already shaped, each tied to specific items in the refined backlog, each with the rationale on the page (this goal because the Initiative's top metric is X and these items move it). The PO picks one, sharpens it, or asks for a different one. The team commits in the room. The hour goes to discussing what to commit to, not to reconstructing capacity from scratch and writing goal options under time pressure.
- Reads team velocity over a rolling window the team agreed on (six sprints is a common default), this sprint's planned capacity (leave calendars, on-call roster, scheduled meetings), the refined-and-DoR-clean backlog from refinement-prep-agent, last sprint's carry-over items, the parent Initiative's current state and top metric, the previous sprint's Sprint Goal and verdict (hit / partial / missed) for context, the team's pattern of Sprint Goals across the last six sprints (so the drafts read in the team's voice), product-analytics signals tied to the active Epics, and open customer escalations the team owns.
- Produces three outputs. First, two or three draft Sprint Goal candidates in the Confluence Sprint Planning page, each a paragraph in the team's voice, each tied to specific backlog items, each with a one-line rationale. Second, a draft Sprint Backlog per candidate goal: which items support which goal, a capacity-check verdict per option, items needed but not yet refined, items DoR-clean and ready. Third, the original planning briefing: realistic capacity for this sprint, backlog candidates ranked by PO priority and DoR-readiness, risks carried over from last sprint.
- Cadence runs the morning of Sprint Planning, also a draft 24 hours before so the PO can edit before the room walks in.
- Audience is the product owner as primary reviewer, the tech lead for technical sanity, the dev team in the session.
- Final call is the team's. The agent drafts goal candidates. The PO sharpens. The team commits to one. The agent never commits a goal to Jira sprint metadata. That happens after Sprint Planning, when the team commits to it together.
- Verdict: new. The dream team skipped planning. In my experience Planning is the second-most-important event after the Daily Scrum and it deserved its own prep agent. Same shadow-mode discipline as refinement-prep: draft in plain text for the first week, then enable Confluence write access where the agent updates the planning page directly.
retro-prep-agent
- Before the retro, this agent has already done the data work and drafted candidate actions for the team to react to. The team walks into the retro to a Confluence page with the numbers laid out (cycle time delta, scope churn, Sprint Goal verdict), the prior retro's actions tracked for completion (which ones moved, which got promised again and forgotten), three candidate themes drawn from the brutal-facts patterns and labelled with their recurrence count ("this is the third retro discussing PR review time"), and a draft action candidate for each theme: concrete next steps in the team's typical action-item style, with a proposed owner and a check-in date. The team accepts, edits, or rejects. The hour goes to deciding what to try next, not to reconstructing what happened or fishing for a new idea when last retro's idea did not work.
- Reads last sprint's standup-update posts, last sprint's brutal-facts flags, last sprint's Sprint Goal verdict (hit / partial / missed), Jira metrics for the sprint just ended (cycle time, scope churn, carry-over), the previous retro's action items and their completion status, the history of retro action items across the last quarter (which patterns recur, which fixes worked, which did not, which themes the team has discussed three times without resolution), the team's agreed retrospective format (Start/Stop/Continue, 4Ls, Glad/Sad/Mad, whichever the scrum master runs), and the team's retro board on Miro or FigJam if that is where the team runs them.
- Produces a retro starter pack pinned to the Confluence retro page. Sections: what the data says happened this sprint (numbers, no narrative), the prior retro's actions and which moved, three candidate themes labelled with recurrence count and one-paragraph framing each, and a draft candidate action per theme with concrete proposed next steps in the team's typical action-item style. Each candidate action has: what to try, who would own it, what success looks like, when to check. Marked clearly as
[draft, team to confirm/edit/reject]. The agent does not write the retro outcome. The team writes that. - Cadence runs the morning of the retro.
- Audience is the whole team, scrum master facilitating.
- Final call is the team's. The candidate actions are starting points so the team is not fishing for ideas in the room when last retro's idea did not work. The team picks one, edits one, rejects one, invents a new one. The scrum master holds the line: agent drafts are starting points, the team owns the conversation.
- Verdict: make. The dream-team original was a longitudinal synthesiser. That one still exists as retro-synthesis-agent. This one is the per-sprint sibling. Different cadences, different outputs, both belong. Same shadow-mode discipline: draft in a channel for the first week, then enable Confluence write access where the agent updates the retro page directly.
retro-synthesis-agent
- The longitudinal counterpart to retro-prep. The agent that reads every retro across a quarter and tells you whether the team is fixing what it keeps complaining about.
- Reads every retro's notes, action items, and themes from the last 4-12 sprints (Confluence retro pages or whichever retro tool you use).
- Produces a quarterly synthesis in Confluence: themes that keep coming up sprint after sprint and never close, themes that surfaced and were genuinely fixed, a short paragraph per recurring theme summarising what the team has tried and what has not worked.
- Cadence runs at the end of every sprint as a partial pass, full pass quarterly.
- Audience is the scrum master, engineering lead, product owner, sometimes the EM above the team.
- Pain it removes is the team promising to fix the same three things every quarter and nobody noticing the pattern.
- Verdict: take. The dream-team description holds.
sprint-goal-tracker-agent
- The agent that watches the Sprint Goal so it does not get written at planning and forgotten until review.
- Reads the Sprint Goal as written in Jira sprint metadata or Confluence, the items linked to the goal, their status and effort burned, days remaining in the sprint.
- Produces a one-line trajectory (on track, drift on item X, off-goal) plus a one-paragraph projection: at current pace the goal lands on day Y, two days late. Linked to the items at risk. The trajectory line also lands inside the standup-update one-pager and is a prompt for the Daily Scrum conversation, not a verdict.
- Cadence runs daily.
- Audience is the product owner, scrum master, dev team.
- Pain it removes is Sprint Goals that exist on paper and never get checked.
- Verdict: new. I split this out because the Sprint Goal is the commitment the Scrum Guide is most explicit about and the one teams skip most often in practice.
team-dora-agent
- The four-numbers card.
- Reads the CI/CD pipeline (deployment frequency, build success), the incident management tool (MTTR, change-failure rate), and GitHub joined to the CI/CD pipeline (lead time for changes, computed from the first commit on a PR through to the production deploy timestamp. You need both inputs because GitHub alone does not know when something hit production).
- Produces a weekly DORA card in the team channel and on the transparency scoreboard: deployment frequency, lead time for changes, change failure rate, mean time to recovery. Trend arrow per metric. No commentary.
- Cadence updated daily, summarised weekly.
- Audience is the engineering lead, dev team, scrum master, with leadership reading via the scoreboard.
- Pain it removes is engineering improvement debates that run on opinion. DORA is the smallest set of numbers the Accelerate research (Forsgren, Humble, Kim) found correlate with performance. The work was acquired by Google in 2018.
- Verdict: take. Watch for Goodhart drift inside the first quarter. Once you measure against DORA, deployment frequency tends to rise because deploys get sliced. Change-failure rate tends to fall because incidents get reclassified. The agent will not catch this. The engineering lead has to.
Tier 2. Scrum of Scrums and multi-team coordination agents
Two to seven teams running on a shared cadence and needing to align, with one of these agents (the portfolio rollup) operating at department or portfolio scale across multiple programs. Five agents below stitch the team-level signal into a program picture and watch the seams between teams. The sixth sits in the repo. The Scrum of Scrums is a coordination convention, not a Scrum Guide event. Nexus calls the equivalent the Nexus Daily Scrum. SAFe calls it the ART Sync, with the System Demo at PI cadence and PI Planning every eight to twelve weeks. The agents work for any flavour. The cadence labels change, the data they read does not.
cross-team-dependency-agent
- The agent that reads Jira's "is blocked by" and "blocks" links across every participating team's board so the SoS does not spend twenty minutes asking each team for a status check.
- Reads dependency links across all participating teams' boards, cross-team Epic links, the shared component ownership matrix in Confluence, recent commits to shared repos, dependency-tagged Slack threads in cross-team channels.
- Produces a dependency one-pager in the SoS channel: dependencies due this week with status, dependencies that slipped with new ETA from the owning team, dependencies newly added in the last 24 hours, orphan items (linked but no owning team has it on their sprint). Each line names both teams.
- Cadence runs daily, posted 30 minutes before the SoS. Also on-demand for ad-hoc reviews.
- Audience is the RTE or program manager, tech leads from each team, group product manager.
- Pain it removes is the SoS that opens with twenty minutes of cross-team status check.
- Verdict: new.
integration-readiness-agent
- During the week leading up to a system demo or integration milestone, this agent has already given the room an honest go / no-go before anyone walks in. The RTE and tech leads walk in to a card showing per-team status, what specifically is blocking each team, the smallest set of decisions needed to unblock, and a projected confidence level on the go decision. Plus draft proposed unblock actions per blocker: who would own each, what the next test should look like, what the team is waiting for. The room stops opening with thirty minutes of "is everyone ready" and starts where it should: at the blockers and the decisions that unblock them.
- Reads branch state across all participating repos, integration-environment deploy status, feature-flag state for the integration in question, integration test pass rates, contract-test results for cross-team APIs, cross-team Jira items tagged for this integration, the integration plan and its dependencies, and the prior integration's outcome (what shipped, what failed, what we learned).
- Produces an integration readiness card in the SoS channel and pinned to a Confluence integration page: per-team status (ready / not ready / blocked), specific blockers per team, draft proposed unblock actions per blocker (with proposed owner and next test), the smallest number of decisions needed to unblock, projected go / no-go with a confidence level (low / medium / high based on how many blockers are decisions vs dependencies).
- Cadence runs daily during the week leading up to integration date, then continuously the day of.
- Audience is the RTE, principal engineer, tech leads, group product manager.
- Final call is the room's. The agent assembles the data and drafts the unblock actions. The room decides go or no-go, accepts or edits the unblock actions, and owns the consequences.
- Pain it removes is every team thinking the others are ready while one team is three days behind and the integration meeting where the first half goes to status and the second half to a hurried decision the team did not have time to think about.
- Verdict: new.
multi-team-sprint-rollup-agent
- The agent that stitches each team's sprint-end signal into a single program-level read so the program manager stops chasing six teams for status.
- Reads each team's Sprint Goal and verdict from sprint-goal-tracker-agent (hit / partial / missed), Jira Epic and Initiative progress across teams, multi-team OKR progress, the standup-update output for each team.
- Produces a program-level rollup in the program channel: one line per team, one paragraph per Initiative covering what moved, what slipped, what is at risk, plus a single paragraph at the top summarising what the data says about the sprint just ended.
- Cadence runs at the end of every sprint, the morning after each team's review.
- Audience is the program manager, RTE, group product manager, engineering managers, leadership audience for the program.
- Pain it removes is hand-assembling a rollup deck every fortnight by chasing six teams for status.
- Verdict: make. The dream-team project-or-product-updates was a single-team agent escalating to leadership. This is the multi-team version, fed by the team-level agents instead of reading raw Jira at program scale.
program-risk-radar-agent
- The agent that lifts risk to where risk compounds: across teams, dependencies, integrations, milestones.
- Reads every team's RAID log (and prompts them to start one if they do not have one), Jira items flagged at risk across teams, the dependency-agent output for slipping dependencies, the integration-readiness-agent output for at-risk integrations, customer escalations tagged to a program initiative, deadlines and milestone dates from the program plan.
- Produces a risk register update in the SoS channel: new risks since yesterday, risks whose probability or impact moved, risks closed because the underlying issue resolved, top three risks the program leadership should know today. RAID-style format.
- Cadence runs daily as a summary, weekly as a deep pass.
- Audience is the RTE, program manager, group product manager, sometimes the portfolio level above.
- Pain it removes is risks raised in a team retro that never travel up or that travel up too late to do anything about.
- Verdict: make. The dream-team risk-radar was single-team. Risk is RAID-discipline (probability-impact scoring, mitigation owners, residual risk after mitigation), which brutal-facts does not cover. A single-team risk-radar still pays for itself where there is no PM keeping a register. Lifted here because cross-team risk is where dependencies, integrations, and milestones compound and that is where the data is most worth reading.
portfolio-sprint-rollup-agent
- At the end of every sprint, this agent has already stitched together what happened across every program in your portfolio. The portfolio leader walks in to a single document with a portfolio-level paragraph at the top, one paragraph per program covering Sprint Goal verdict and headlines, the movement of the strategic bets, the cross-program risks that compounded, and the open questions for the portfolio table. The portfolio leader stops chasing every program manager for a status. The portfolio's next-sprint prioritisation conversation starts from a real picture, not from a hand-curated rollup nobody is sure is current.
- Reads each program's multi-team-sprint-rollup output, the portfolio-level OKR scorecard subset, the strategic-bets register, cross-program dependencies if tracked, customer escalations tagged to portfolio-level initiatives, portfolio milestones and deadlines, last sprint's portfolio-rollup for delta tracking.
- Produces a portfolio-level rollup landed in the portfolio Confluence space, mirrored to a portfolio Slack channel. Sections: a portfolio-level paragraph at top summarising what the data says about the sprint just ended at portfolio scale, one paragraph per program covering Sprint Goal verdict / headline / what shipped / what slipped / what is at risk, strategic-bets status update (how each bet moved this sprint), cross-program risks that compounded this sprint, open questions for the portfolio leadership table.
- Cadence runs at the end of every sprint (typically fortnightly), the morning after each program's multi-team-sprint-rollup runs.
- Audience is the portfolio manager / portfolio director, head of engineering at portfolio scale, head of product at portfolio scale, COO / CTO if the portfolio is at C-suite level, steering committee in larger orgs.
- Final call is the portfolio leader's. The agent rolls up the data. The leader interprets and acts. The agent never updates the strategic-bets register, the OKR scorecard, or any program's rollup directly. It reads each program's output, stitches the portfolio picture, and lets the leader decide what to do next.
- Pain it removes is the portfolio leader hand-assembling a rollup deck every fortnight by chasing five program managers for status, plus the portfolio prioritisation conversation that starts cold because nobody has had time to assemble the cross-program picture.
- Verdict: new. This is the agent that closes the gap between Tier 2 program rollups and Tier 3 LT readouts at sprint cadence: portfolio-level sight every fortnight, not just every quarter.
Tier 3. The LT cadence agents
Skip this section if you run one team. Skim it if you run a program, because you will want it when you grow. Read it if you are at the LT cadence (head of product, GM, COO, steering committee). The order matters: get the team-level agents working before you wire any of these up and earn the right to the rest by getting the basics clean.
The LT cadence covers anything where the unit of work is the quarter. Seven agents here, plus two I dropped from the main article that sit in the repo. They prepare the artefacts the leadership table wants, not the artefacts product and delivery polish out of habit.
A note on QBP and QBR. Many orgs run a single end-of-quarter QBR that does both review and forward-look in one event. I am splitting them into two agents because the planning half and the review half need different inputs, ship at different points in the cycle, and serve different decisions. If your org runs one combined event, run both agents and stitch the output. The artefacts being two does not require the meetings to be two.
qbp-pack-prep-agent
- In the final two weeks of the current quarter, this agent has been assembling the QBP pack so the leadership table walks into planning with the work already done. The LT sees proposed objectives drawn from the current quarter's running actuals, candidate key results per objective with evidence and rationale, the OKR carry-over decision per key result (which survive, which die, which mutate), the strategic-bets register snapshot at quarter-start, capacity allocation by bet drawn from Jira Plans, a hypothesis-evidence-spend line per bet, and the top three open strategic questions for the planning room. The leadership table picks the objectives, sharpens the KRs, and decides the bets. The agent has done the assembly so the room can spend its time on the actual decisions, not on whose deck has the latest numbers.
- QBP is Quarterly Business Planning, run before the next quarter starts. What we will commit to next, why, and against which evidence.
- Reads the current quarter's running actuals (north-star metric, OKR scorecard, strategic-bets progress), the strategic-bets register, the OKR scorecard from the current quarter (including a carry-over view of which key results survive, which die, which mutate), Jira Plans (advanced roadmap) for cross-team capacity forecasts and in-flight initiative state, the opportunity-tree from opportunity-tree-maintenance-agent, win/loss themes from the current and prior quarter, and market intelligence and competitive notes if the team keeps them.
- Produces a QBP pack in the leadership Confluence space: proposed objectives for next quarter, candidate key results per objective with evidence and rationale, the OKR carry-over decision per key result, the strategic-bets register snapshot at quarter-start, capacity allocation by strategic bet drawn from Jira Plans, hypothesis-evidence-spend line per bet, top three open strategic questions for the planning room.
- Cadence runs in the final two weeks of the current quarter, on-demand the morning of QBP. The meeting itself happens before the next quarter begins.
- Audience is the head of product, GM, COO, steering committee, function leads attending the planning.
- Final call is the leadership table's. The agent does not pick the objectives. The pack is candidates and a snapshot of where the bets stand. The LT picks. The agent never updates the OKR sheet, the bets register, or the capacity allocation directly. The PM or whoever the LT delegates updates the canonical artefacts after the planning meeting.
- Pain it removes is the new quarter starting from a blank slide deck or, worse, the same objectives that did not move last quarter renamed for the new one.
qbr-pack-prep-agent
- In the first two weeks after the quarter ends, this agent has been assembling the QBR pack so the head of product is not stuck polishing slides until midnight before the meeting. The LT walks in to the same pack everyone else has already read: north-star trend with the just-finished quarter's movement, OKR scorecard, OKR confidence-trend chart per key result (the diagnostic that says we missed because we kept dropping confidence and did nothing, versus we missed because the world changed in week eight), strategic-bets status per bet, planned-versus-delivered roll-up from Jira Plans, top three wins with evidence, top three misses with a root-cause flag, proposed top three priorities for next quarter, and open questions for the executive table. The team that built the work, the team that ran it, and the team that funded it all see the same data. The conversation goes to root cause and to next-quarter calls, not to whose deck has the latest numbers.
- QBR is Quarterly Business Review, run right after the quarter finishes. What happened, what we learned, what to take into the next QBP.
- Reads the north-star metric warehouse query, the OKR scorecard sheet, Jira initiatives at the epic-and-above level, the Jira Plans (advanced roadmap) planned-versus-delivered view for the just-finished quarter, product-analytics funnels, customer-feedback channels, support-ticket category trends, win/loss notes from the just-finished quarter, design-partner status, the strategic-bets register, and the prior quarter's QBR pack for delta tracking.
- Produces the full standard QBR pack as a single document in the leadership Confluence space, mirrored to a Slack thread. Fixed sections (above) so quarter-on-quarter comparison stays valid.
- Cadence runs twice a week through the final two weeks of the quarter and the first week after the quarter ends, on-demand the morning of the QBR.
- Audience is the head of product, GM, COO, board members in smaller orgs, steering committee in larger orgs.
- Final call is the leadership table's. The agent flags root causes. Humans analyse them. The agent surfaces evidence excerpts. Humans interpret. The proposed top-three priorities are candidates for the next-quarter conversation, not commitments.
- Pain it removes is the polishing economy at quarter-end: the two weeks of slide polishing across product, delivery, and finance that nobody reads twice.
okr-checkin-agent
- The agent that runs the weekly OKR check-in (Christina Wodtke's discipline, adapted to a Monday-commitment / Friday-win split) so the OKR sheet is not opened only the day before the meeting. The confidence rating per key result is the part that matters. The trend across weeks tells you whether you will hit the quarter.
- Reads the OKR sheet (a sheet, Confluence, wherever yours lives), product-analytics events tied to each key result, Jira initiative progress, last week's check-in notes for delta.
- Produces two short documents per week. Monday: which key results moved last week, which did not, what the team committed to this week. Friday: which commitments shipped, which slipped, confidence rating per key result for the rest of the quarter, plotted against last week's number. The trend is the signal. Lands in the product-leadership Slack channel and is appended to the OKR sheet as a comment row.
- Cadence runs Monday 7am and Friday 4pm team-time.
- Audience is the head of product, product managers running each objective, GM as a read-only audience.
- Pain it removes is OKRs that get treated as a quarterly artefact instead of a weekly discipline.
roadmap-status-agent
- The agent that keeps the roadmap honest with what has happened, not what the product manager remembered to write down before the monthly meeting.
- Reads Jira initiatives at the epic-and-above level, Jira Plans (advanced roadmap) for cross-team plan state and dependency view, ProductBoard or Aha or Jira Product Discovery (whichever the org uses), engineering capacity estimates from delivery, dependency notes, last month's roadmap snapshot for delta.
- Produces a weekly drift digest in the product channel covering initiatives that slipped a milestone or had a dependency move, plus a monthly structured roadmap-delta document: what shifted, why per the data not per opinion, which initiatives are now at risk against their committed quarter, which are running ahead. Lands in the product Confluence space and is linked from the public or internal roadmap view.
- Cadence runs weekly as a digest, monthly as a deep document.
- Audience is the head of product, GMs, design-partner cohort if the roadmap is shared with them. If you have a Tier 2 program manager, route the daily drift signal to them via cross-team-dependency-agent rather than into the LT channel. The LT does not want a daily Slack ping every time an initiative twitches.
- Pain it removes is the hand-curated monthly roadmap update that is one sprint behind reality.
opportunity-tree-maintenance-agent
- The agent that keeps the opportunity-solution tree alive, instead of getting built once at the start of the quarter and never being touched again. The opportunity-solution tree is Teresa Torres's continuous-discovery framework. The tree itself is PM-owned. The agent is a draft layer between raw research and the canonical tree. New opportunities are flagged as candidates, not auto-merged, because the tree is a structured artefact rather than a feedback inbox. The PM and the discovery trio decide what becomes an opportunity.
- Reads discovery interview transcripts (Notion has a community MCP server if you use it), customer-support ticket categories, in-product feedback, NPS verbatims, sales-call notes if available, and the current opportunity-solution tree on Miro, where most teams keep it.
- Produces a draft updated opportunity-solution tree. New opportunities surfaced from this week's interviews are flagged as candidates. Existing opportunities get a frequency count and a recency timestamp. Branches that have not had a new data point in 60 days are flagged for pruning. Lands as a new version of the tree in the discovery workspace, with a Slack summary of what changed.
- Cadence runs Friday afternoon, after the week's interviews are transcribed.
- Audience is the head of product, product managers, innovation leads, and design researchers.
- Pain it removes is the opportunity tree that gets built once and is never updated, so by week six, it lies.
win-loss-synthesis-agent
- The agent that turns the win/loss program that exists on paper into an actual deliverable.
- Reads win/loss interview notes, CRM closed-won and closed-lost reasons, sales-call transcripts where consented, competitive intelligence notes, product-analytics activation funnels for the win cohort, churn-survey responses for the loss cohort.
- Produces a monthly digest (top three win patterns, top three loss reasons this month, evidence excerpts, delta against the rolling quarter) and a quarterly synthesis (full pattern document with recommended product, pricing, positioning, and process changes). Lands in the leadership Confluence space.
- Cadence is monthly digest on the first business day, quarterly synthesis in the last week of the quarter.
- Audience is the head of product, GTM lead, GM, sales leadership, design-partner program owner.
- Pain it removes is the win/loss program that only produces a synthesis when the head of product carves out a Friday for it.
- This agent assumes a win/loss program already exists with at least interview notes and tagged CRM reasons. If you do not have that yet, build the program first. The agent is a synthesiser, not a substitute for the work of running the interviews.
portfolio-bets-readout-agent
- The agent that prepares the monthly steering or board readout so the head of product is not writing the same narrative paragraphs they wrote last month with different numbers.
- Reads the strategic-bets register, north-star metric trend, OKR scorecard, capacity allocation by bet, design-partner state, win/loss themes for the month, top three open executive questions from the prior month's readout.
- Produces an executive-grade document. One page per strategic bet covering hypothesis, evidence-to-date, current spend versus committed, time-since-last-pivot, plus a colour-coded signal per bet on each of those dimensions. The LT names the action. The flag is the data prompt, not a kill-or-double-down recommendation dressed up. Plus a one-page cover with north-star trend and OKR scorecard. Lands in the steering Confluence space.
- Cadence runs monthly, five business days before the steering meeting (so the LT has time to read the doc before the meeting rather than walking in cold).
- Audience is the steering committee, board, GM, head of product.
- Pain it removes is the polishing economy at portfolio level, the leadership-tier successor to what project-or-product-updates was attacking in the dream-team piece.
The catalogue at a glance
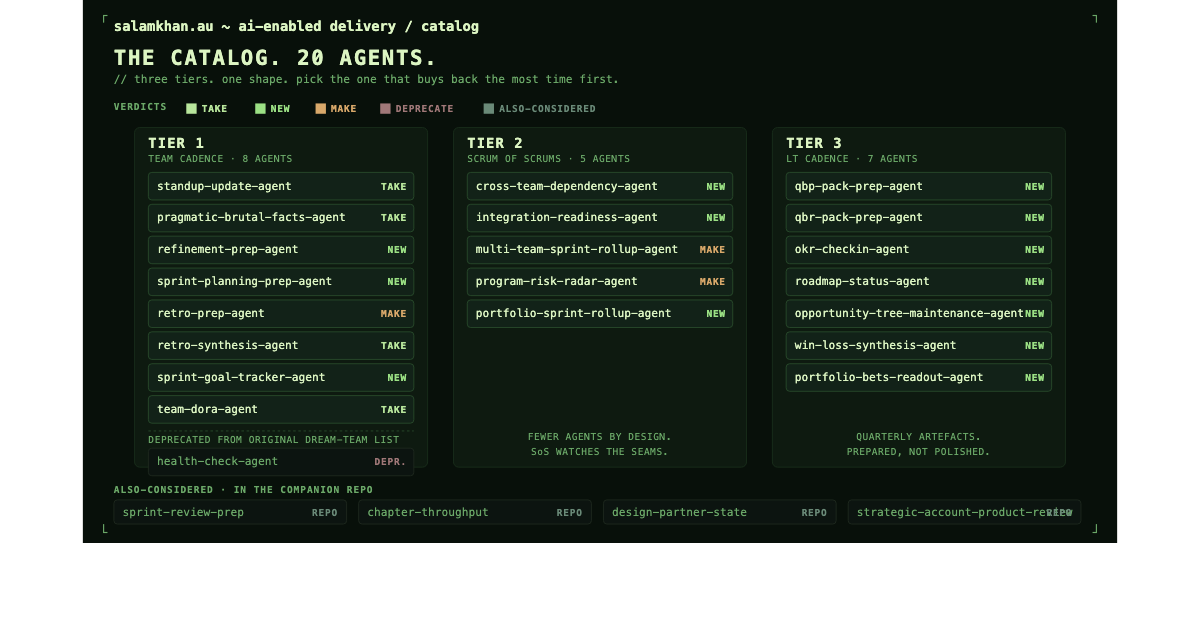
The catalogue in one panel. Twenty agents, colour-coded by verdict. Take, make, new, deprecate, and the four cuts that sit in the repo. Generated by Author using Claude.
The transparency-scoreboard
I am calling the transparency-scoreboard out separately because it is not an agent. It is a read-only dashboard showing your team's real numbers in one place where everyone sees the same view, from the engineer to the GM to the newest grad on the team.
The point is to remove the slide-polishing step. Every dashboard tool has filters, exclusion flags, and metric definitions that someone with admin rights can change, so the polishing layer does not disappear so much as move from the deck to the dashboard definition. The dashboard definition is a smaller surface to audit than a deck per quarter, but it is not zero. Pick someone outside the chain of command to own those definitions and write them down where the team can see them.
I have seen quarter-end numbers get a haircut before they go upstairs more times than I want to count. The scoreboard takes that move off the table.
Setup is whichever dashboard tool you already have: Tableau, Looker, Metabase, a Notion page with embedded widgets, an Apple Numbers file with auto-refresh if your team is small enough. The discipline matters more than the tool you pick.
The agents in this catalogue all point at the scoreboard. Brutal-facts references the same baseline. The team-DORA card pins to it and roadmap-status drift uses the same metric definitions. One source of truth, with every agent reading from it and leadership seeing it without a filter.
The agent we did not build
The dream-team article named a health-check agent that would read retro themes, chat tone, and 1-on-1 patterns and surface burnout signals to leadership.
I am not going to tell you to build that one.
The signal is real. People burn out and the patterns show up in chat and in 1-on-1 notes. The problem is the engineering and the failure mode.
An agent that scores chat tone is reading every public message your team posts and assigning it a sentiment. Tone moves with the time of year as much as with deadlines, so the false-positive rate on burnout from chat alone is high. An agent that reads 1-on-1 notes is asking the most sensitive document the manager-direct relationship produces to make a judgement on the human in the room. Whose consent did the agent get to read those notes?
If you build this agent and it gets it wrong, you will have a conversation about surveillance with your team. If you build it and it gets it right, you will have a conversation about why the agent noticed before the manager did.
Humans paying attention pick up burnout signals. Make sure your retros and your 1-on-1s have space for them to come up. The agent is not the right tool for the job.
Verdict: deprecate.
The repo
I named twenty agents in this article and twenty-four in the repo. The four cuts (sprint-review-prep, chapter-throughput, design-partner-state, strategic-account-product-review) sit in agents/also-considered/ because they are real and buildable, just not where I would tell you to start.
Find the SK-AI-delivery-agents repo on GitHub.
Each agent has its own markdown file with the same shape every time: cadence event, cadence frequency, inputs, outputs, audience, pain it removes, verdict on the dream-team original if relevant, and a prompt-shape sketch in prose (no code, no YAML, same logical-level position as this article).
It is a reference, not a project. MIT licensed, so fork it, adapt it to your stack, and build the ones I did not name.
. . .
The honest bit
The agents do not save you from a broken team.
Dirty data, out-of-date tickets, gamed metrics. The agents will get all of those wrong with confidence. Read-only does not mean safe either, because an LLM reading two correct sources can still infer a wrong link between them. The team channel is the right first audience because the team catches wrong links. Leadership channels are not, because leadership will not.
They make a clean team faster. They give a dishonest team a more authoritative way to lie.
I see this directly in every team I have worked with. The 2025 DORA State of AI-Assisted Software Development report names it: AI does not fix a team but amplifies what is already there, so strong teams get better with it and struggling teams find their existing problems amplified. The brutal-facts agent reads Jira straight, which means a team gaming Jira gets clean numbers from the agent. The DORA card has the same problem with CI/CD: deployments batched to flatter the metric, card flatters the metric. The agent does not see through gamed inputs. It rewrites them in plain English and posts them at 6am. That is why I keep saying the easy half is the agents and the hard half is the culture.
The trust gap is real and it is widening. Stack Overflow's 2025 Developer Survey reports 84% of professional developers now use AI tools, up from 76% in 2024. Trust in the accuracy of AI fell from around 40% the year before to 29% in the same period. 66% say they spend more time fixing "almost-right" AI-generated code than they used to. Adoption has gone mainstream. Trust has not followed. That is why every agent in this catalogue goes into the team channel first. The team is the audience that catches the almost-right output before it gets to a room where the inference will be acted on without anyone noticing.
If your team does not want to know what the brutal facts are, do not start with brutal-facts. Start with standup-update, which is informational rather than confrontational. Earn trust first, before you wire up the agent that names the drift.
A second risk lives at the cross-team and leadership layers that the team-level lessons do not have. Leadership channels are the wrong first audience for any of the Tier 2 or Tier 3 agents. The team channel is where wrong inferences get caught. The steering committee channel is where wrong inferences get acted on. Run every Tier 2 and Tier 3 agent in shadow mode for at least one full cycle before its output goes to the audience it is meant for. One sprint for the rollup agents. One quarter for the QBP, QBR, and bets readout. Confidence is built by being wrong in low-stakes rooms first.
If you are at the LT cadence, start with the OKR check-in and the QBR pack. Both are weekly or quarterly disciplines that exist on paper at most companies and rarely run with discipline. The agent does not impose the discipline. It removes the work that gives the team a reason to skip it.
If you build the first three or four, give yourself a sprint of operating with them, not two weeks. Two weeks tells you whether the team will engage with the output. A sprint tells you whether the next agent gets prioritised, whether leadership funds the security review, and whether the data hygiene work gets done. Most teams that try this will not finish all twenty. Build the one that buys back the most time first, on the assumption that it might be the only one you ship this year. If it pays for itself, the next one is easier to fund.
The data work is the part most teams underestimate. McKinsey's 2025–2026 research on scaling agentic AI puts it directly: eight in ten companies cite data limitations as the primary roadblock to scaling agents. Only 7% describe their data as fully AI-ready. The ratio is consistent with the experience of every delivery team I have worked with. The runtime is cheap. The MCP servers are free. The data sitting behind them is the part that takes the work and the part that determines whether the agent says something true or something authoritative-and-wrong.
The prompt is the easy part. The data hygiene and the auth review are the rest.
Start anyway. The first agent is the smallest piece of useful work most delivery teams can ship this quarter. Those are also where the real work is and where the team learns the most about itself. If you are building any of it on yours, I want to hear how it lands.
With love and Chai.
Salam.
P.S. This piece is the start of a conversation, not the end of one. If you build any of these, ship a sharper version, or land on a different shape that works for your team, I would love to hear about it. Email me at salam@9t5.com.au.